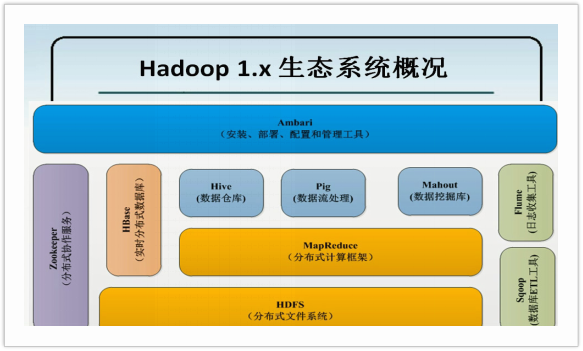
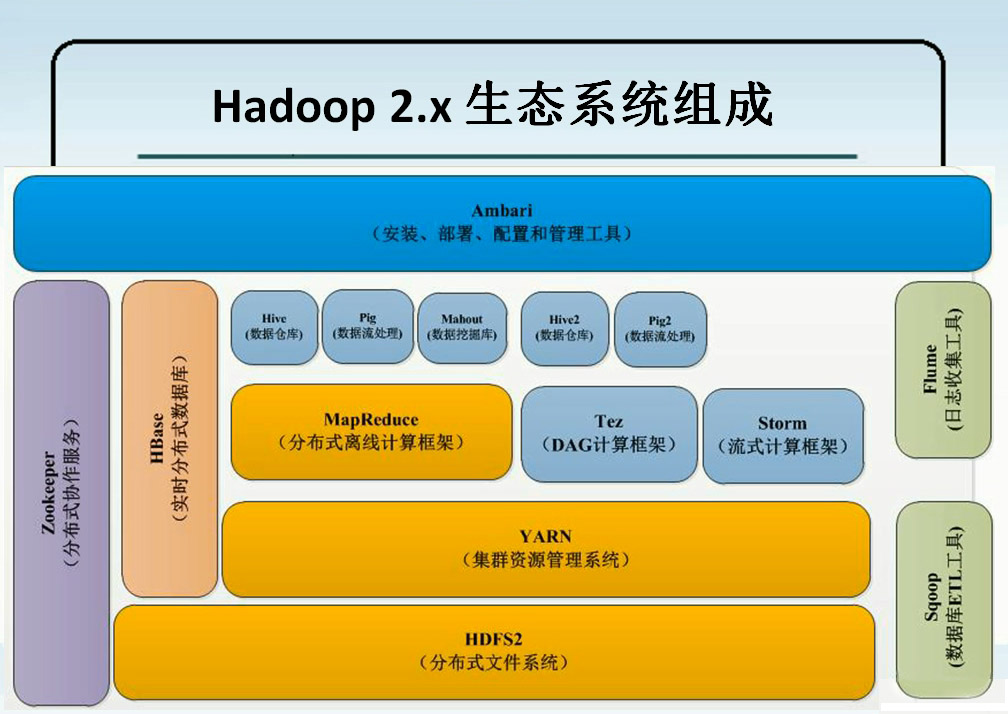
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
Sqoop:
Sqoop将关系型数据库中的数据与HDFS(HDFS文件,HBase中的表,Hive中的表)上的数据进行相互导入导出。
ETL: 提取->转换->加载
从数据库中获取数据,并进行一系列的数据清理和清洗筛选,将合格的数据进行转换成一定合格的数据进行存储,将格式化的数据存储到HDFS文件系统上,以供计算框架进行数据分析和数据挖掘。
格式化数据:
- TSV格式:每行数据之间以【制表符\t】进行分割
- CSV格式:每行数据之间以【逗号】进行分割
Flume:收集各个应用系统和框架的日志,并将其放到HDFS分布式文件系统的相应制定的目录下。
架构
对于分布式系统和框架的架构来说,一般分为两部分。第一部分:管理层,用于管理应用层的,第二部分:应用层(工作的)。
Hadoop的五个守护进程:
HDFS:
NameNode: 属于管理层,用于管理数据的存储
SecondaryNameNode: 也属于管理层,辅助NameNode进行管理
DataNode: 属于应用层,用户进行数据的存储,被NameNode进行管理,要定时的向NameNode进行工作汇报,执行NameNode分配的分发的任务。
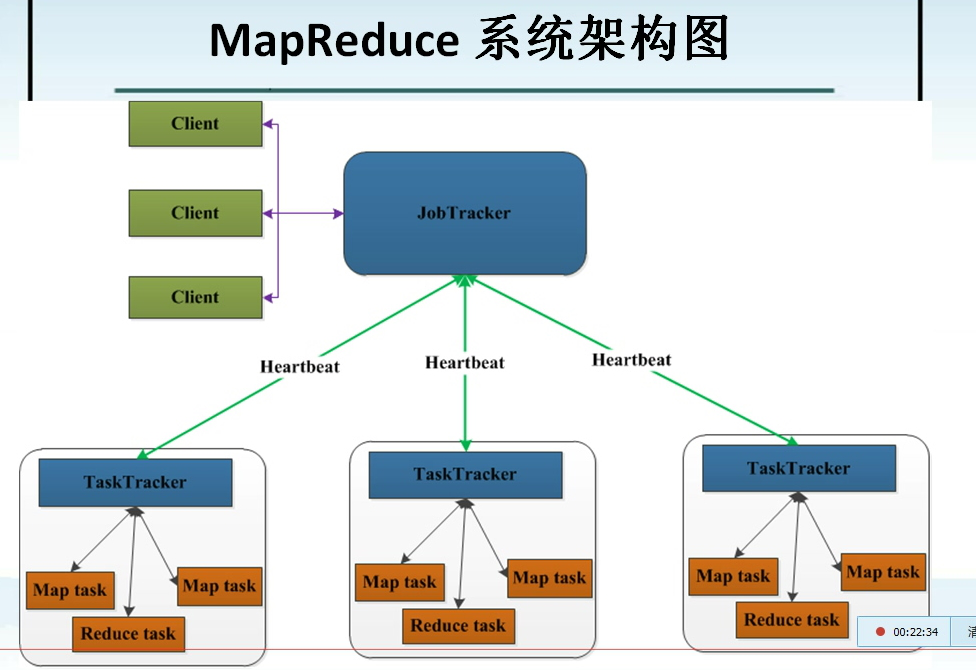
MapReduce 分布式的并行计算框架
JobTracker : 属于管理层,管理集群资源和对任务进行资源高度,监控任务的执行。
TaskTracker : 属于应用层,执行JobTracker分配分发的任务,并向JobTracker汇报工作情况。
NameNode,存储文件的元数据
文件名称
文件的目录结构
文件的属性(权限,副本数,文件的生成时间)
文件对应的Block块存储在DataNode上
Hadoop安装部署模式
单机模式: 只有一个JVM进程,没有分布式,不使用HDFS,通常用于调试。
伪分布式模式: 只有一台机器,每个Hadoop守护进程都是一个独立的JVM进程,通常用于调试。
完全分布式模式: 运行于多台机机器上,真实环境。
设置普通用户无密码sudo权限
编辑/etc/sudoers文件。
vi /etc/sudoers”,输入”i”进入编辑模式,
找到这一 行:”root ALL=(ALL) ALL”在起下面添加”xxx ALL=(ALL) ALL”(这里的xxx是你的用户名),然后保存(就是先按一 下Esc键,然后输入”:wq”)退出。
安装环境
1)安装JDK
第一步,解压/opt/software/jdk-6u45-linux-x64.bin到/opt/modules/
第二步,配置环境变量
12export JAVA_HOME=/opt/modules/jdk1.6.0_45export PATH=$JAVA_HOME/bin:$PATH以root用户登录,执行以下命令,使配置生效
1#source /etc/profile卸载自带JDK。
1yum -y remove java-*.*查看目前系统的JDK:
1rpm -qa | grep jdk
2)安装hadoop
第一步,解压 #tar -zxvf hadoop-1.2.1-bin.tar.gz
第二步,移动 #mv hadoop-1.2.1 /opt/modules
第三步,配置环境变量,编辑【/etc/profile】文件,添加如下内容
1234#HADOOPexport HADOOP_HOME=/opt/modules/hadoop-1.2.1export PATH=$PATH:/opt/modules/hadoop-1.2.1/binexport HADOOP_HOME_WARN_SUPPRESS=1 #添加此项消除hadoop home is deprected的警告以root用户登录,执行以下命令,使配置生效
1#source /etc/profile第四步 测试 Hadoop
第五步 配置hadoop中的JDK安装路径
vim /opt/modules/hadoop-1.2.1/conf/hadoop-env.sh
1export JAVA_HOME=/opt/modules/jdk1.*.*第六步 测试MapReduce 程序
123$mkdir /opt/data/input$cp /opt/modules/hadoop-1.2.1/conf/*.xml /opt/data/input$hadoop jar /opt/modules/hadoop-1.2.1/hadoop-examples-1.2.1.jar grep input output 'dfs[a-z.]+'
Hadoop组件依赖关系,配置Hadoop

关闭防火墙 centOS7的默认防火墙和之前不同。
关闭selinux
vim /etc/sysconfig/selinux
1SELINUX=disable设置永久hostname
vim /etc/sysconfig/network
12NETWORKING=yesHOSTNAME=centOSIP与hostname绑定
vim /etc/hosts
1192.168.41.111 hadoop.dragon.org设置SSH密钥登录 –所有守护进程彼此通过SSH协议进行通道
123ssh-keygen –t rsacd .sshcp id_rsa.pub authorized_keys分别 ssh登录 localhost centOS hadoop.dragon.org 192.168.41.111。
mkdir /opt/data/tem 配置文件需要建立此目录
修改conf下目录配置文件
配置core-site.xml
12345678910<configuration><property> 指定namenode主机名与端口号<name>fs.default.name</name><value>hdfs://hadoop.dragon.org:9000</value></property><property><name>hadoop.tom.dir</name><value>/opt/data/tmp</value></property></configuration>配置hdfs-site.xml
12345678910<configuration> ---设置HDFS的副本数<property><name>dfs.replication</name><value>1</value> --默认是3,伪分布设置成1</property><property><name>dfs.permissions</name><value>false</value></property></configuration>配置mapred-site.xml
123456<configuration><property> <!--定jobtracker的主机和端口号--><name>mapred.job.tracker</name><value>hadoop.dragon.org:9001</value></property></configuration>配置slaves修改成自己设置的域名(指定DataNode和TaskTracker):hadoop.dragon.org
配置masters(指定SecondaryNameNode的位置):hadoop.dragon.org
格式化NameNode启动守护进程,依次开启和关闭
1$ hadoop namenode -format
Hadoop 启动方式及日志、测试
Hadoop启动方式
第一种:
$start-dfs.sh 依次启动namendoedatanode secondarynamenode
$jps 可查看开启的java进程$start-mapred.sh 启动jobtrackertasktracker
$stop-mappred.sh 依次关闭jobtracker tasktracker
$stop-dfs.sh 依次关闭 namenode datanode secondarynamenode
第二种:
$start-all.sh
$stop-all.sh
第三种:分别开启和关闭五个守护进程,开启和关闭顺序相反
$hadoop-daemon.sh start namenode
$ 。。。
$hadoop-daemon.sh stop namenode
hadoop-daemons.sh使用方式和hadoop-daemon.sh类似,不同之处是同时可以启动多台机器上的某个守护进程
日志
以log结尾的日志
通过log4日志记录格式进行记录的日志,采用的日常滚动文件后缀策略来命名文件,内容比较全。
以out结尾的日志
记录标准输出和标准错误的日志,内容比较少,默认的情况,系统保留最新的5个日志文件。
修改conf目录下的hadoop-env.sh中export HADOOP_LOG_DIR可指定日志文件的保存路径。
日志的格式
例如hadoop-root-namenode-centOS.log,分五个部分,用横线隔开,分别表示框架名-开启守护进程的用户名-守护进程名-hostname(运行守护进程的机器名称)-日志格式
测试
HDFS测试
对HDFS文件系统进行查看文件,对文件或者文件的基本操作。(通过命令行的方式交互)
hadoop [–config confdir] COMMAND 默认使用conf目录下的配置
查看文件系统命令
|
|
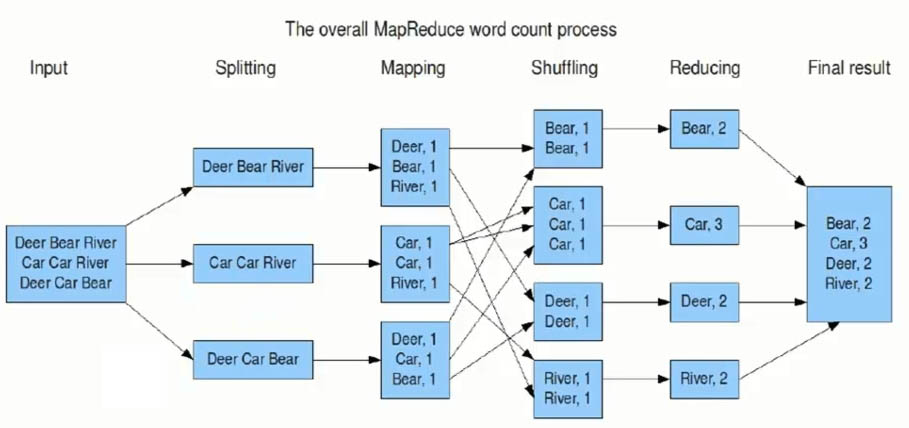
MapReduce程序的测试,单词频率统计WordCount程序。
|
|
运行jar程序,并指定输入输出路径,输出路径由程序自动创建。
打开 hadoop.dragon.org:50030 查看运行状态,打开hadoop.dragon.org:5000查看运行结果。
命令行下查看结果 $ hadoop fs -text /wc/output/part-r-00000 (-cat参数功能同此)
分析启动shell脚本
查看start-all.sh脚本
此shell脚本仅仅在主节点上执行。
首先启动DFS文件系统的守护进程,再启动MapReduce框架的守护进程。
启动HDFS文件守护进程时,调用start-dfs.sh Shell脚本,启动MapReduce守护进程时,调用start-mapred.sh Shell脚本。
查看start-dfs.sh脚本
此脚本运行在DFS文件系统上的主节点上。
如果先启动DataNode守护进程,没有启动NameNode守护进程,DataNode日志文件一直出现连接NameNode错误信息。
NameNode启动,调用的是hadoop-daemon.sh脚本,DataNode和SecondaryNameNode启动调用的是hadoop-daemon.sh脚本。
在启动SecondaryNameNode服务时,通过指定参数【–hosts masters】指定哪些机器上运行SecondaryNameNode服务,由此也验证了配置文件【masters】配置的IP地址为SecondaryNameNode服务地址。
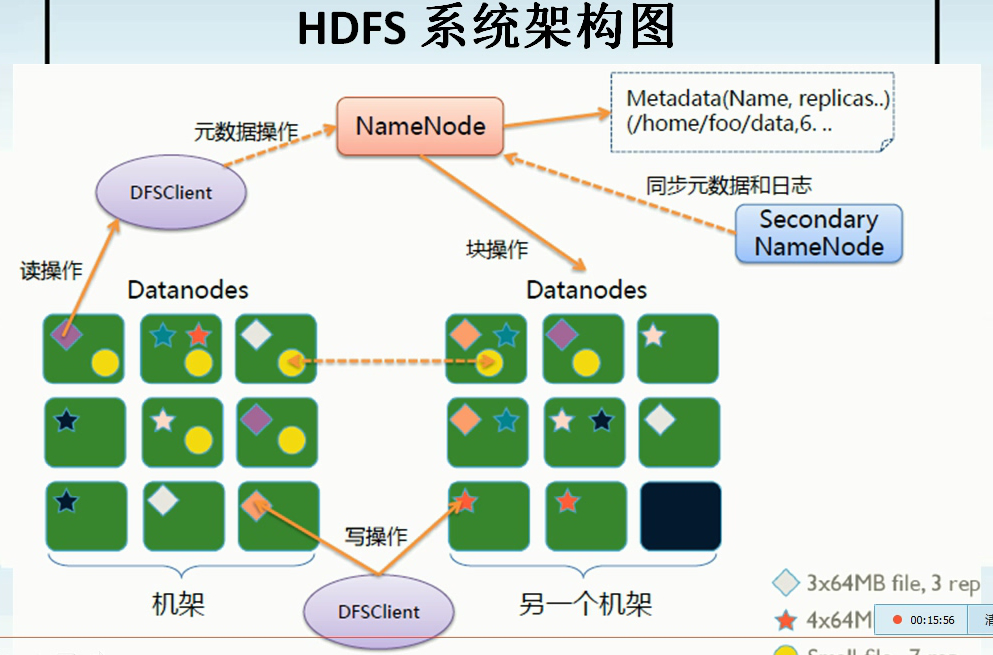
HDFS架构
NameNode
NameNode存储元数据,元数据存在内存之中,保存文件、block和DataNode之间的映射关系。其是一个中心服务器,一个单一节点,负责管理文件系统的名字空间,以及客户端对文件的访问。
NameNode负责文件元数据的操作,DataNode负责处理文件内容的读写请求。 数据流不经过NameNode。
读取文件时NameNode尽量让用户读取最近的副本,其全权管理数据块的复制,它周期性地从集群中的每个DataNode接收心中信号和块状态报告(Blockreport),块状态报告包含了一个该DataNode上所有数据块的列表。
两个重要文件
fsimage:元数据镜像文件(保存文件的目录树)
edits:元数据操作日志(针对目录树的修改操作)
元数据镜像
内存中保存一份最新的
内存中的镜像=fsimage+edits
定期合并fsimage与edits
edits文件过大将导致NameNode重启速度慢
SecondaryNameNode负责定期合并它们
DataNode
DataNode 存储文件内容,文件内容保存在硬盘之上,维护了blockid到DataNode本地文件的映射关系。
一个数据块在DataNode以文件存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据(包括块的长度、块数据的校验和以及时间戳)。
SecondaryNameNode
并非NameNode的热备;
辅助NameNode,分担其工作量;
定期合并fsimage和fsedits,推送给NameNode;
- 在紧急情况下,可辅助恢复NameNode
Client
文件切分;
与NameNode交互,获取文件位置信息;
与DataNode交互,读取或者写入数据;
管理HDFS和访问HDFS。
错误及处理措施
常见的三种错误情况
文件损坏、网络或者机器失效和NameNode挂掉
保障可靠性的措施
文件完整性
CRC32效验
用其它副本取代损坏文件
Heartbeat
- DataNode定期向NameNode发送Heartbeat
元数据信息
FSImage(文件系统镜像)、Editlog(操作日志)
多份存储,当NameNode损坏后可以手动还原
副本放置策略
Hadoop 0.17之前
副本1:同机架本机外的不同节点
副本2:同机架的另一个节点
副本3:不同机架的的另一个节点
其它副本随机挑选
Hadoop 0.17之后
副本1:同Client的节点上
副本2:不同机架中的节上
副本3:同第二个副本的机架中的另一个节点
其它副本:随机挑选
数据损坏处理(corruption)
DataNode读取block时,会计算checksum,如果与创建时的值不同,说明已经损坏。NameNode标记其已经损坏,并复制block。DataNode默认在其文件创建三周后难其checksum。
HDFS常用shell命令及API
常用shell命令
$ hadoop fs -lsr / 查看/目录下的文件
$ hadoop fs -lsr /tmp 查看tmp目录下的所有文件
$ hadoop fs -mkdir /opt/data/test 创建hdfs目录
$ hadoop fs -put /test/01.data /opt/data/test 上传文件到指定目录,可同时上传多个文件
$hadoop fs –text /opt/data/test/01.data 查看文件内容
$ hadoop fs -mv /opt/data/test/01.data /opt/data/test/01.data.bak 重命名
$ hadoop fs -cp /opt/data/test/01.data.bak /opt/data/test/01.data 拷贝
$ hadoop fs -rm /opt/data/test/01.data.bak 删除
$ hadoop fs -rmr /opt/data/test 删除目录及目录下的文件
$ hadoop fs -get /wc/input/co*.xml / 获取文件放到/目录下
$ hadoop fs -getmerge /hdfs /0.data 从HDFS获取/hdfs下的文件并合并成一个放到本地
HDFS API
使用HDFS URL API操作
|
|
使用HDFS FileSystem API操作
须引入hdfs-site.xml和core-site.xml
|
|