MapReduce是一种分布式计算模型框架,解决海量数据的计算问题。其将整个并行计算过程抽象到两个函数。
简述
在运行一个mapreduce计算任务时候,任务过程被分为两个阶段:map阶段和reduce阶段,每个阶段都是用键值对(key/value)作为输入(input)和输出(output)。而程序员要做的就是定义好这两个阶段的函数:map函数和reduce函数。
Map: 对一些独立元素组成的列表的每一个元素进行指定的操作,可以高度并行。
Reduce: 对一个列表的元素进行合并。
一个简单的MapReduce程序只需要指定map()、redue()、input和output,剩下的事由框架完成。
Mapreduce特点
易于编程
良好的扩展性
高容错性
适合PB级以上海量数据的离线处理
相关概念
JobTracker:负责接收用户提交的作业,负责启动、跟踪任务执行。
TaskTracker:负责执行由JobTracker分配的任务,管理各个任务在每个节点上的执行情况。
Job:用户的每一个计算请求,称为一个作业。
Task:每个作业,都需要拆分开来,交由多个服务器来完成,拆分出来的执行单位,就称为任务。分为MapTask和ReduceTask两种。
Map Task
Map引擎
解析每条数据记录,传递给用户编写的map()
将map()输出数据写入本地磁盘(如果是map-only作业,则直接写入HDFS)
Reduce Task
Reduce引擎
从Map Task上远程读取数据
对数据进行排序
将数据按照分组传递给用户编写的reduce()
执行流程
MapReduce编程模型
input -> map()-> reduce()-> output 侧重算法和数据结构
Map任务处理
1)读取文件内容,把每一行解析成key、value对。每一个键值对调用一次map函数。
2)写自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
3)对输出的key、value进行分区。
4)对不同分区的数据,按照key进行排序、分组。相同key的value放到一个集合中。
5)(可选)对分组后的数据进行归约。
Reduce任务处理
1)对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。
2)对多个map任务的输出进行合、排序(归并排序)。写reduce函数自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
3)把reduce的输出保存到文件中。
蒙地卡罗方法—测试集群MapReduce性能
hadoop jar hadoop-examples-1.2.1.jar pi 10 100 运行10map,每个map拆分成100个job
MapReduce程序编写
在MapReduce中,map和reduce函数遵循如下常规格式
map: (K1, V1) list(K2, V2)
reduce: (K2, list(V2))list(K3, V3)
Mapper的接口:
|
|
Reduce的接口:
|
|
Job要引入org.apache.hadoop.mapreduce.Job;FileInputFormat 和FileOutputForma要引入org.apache.hadoop.mapreduce.lib下的包
配置Hadoop-eclipse-plugin
1.打开Eclipse,windowpreferenceshadoop map/reduce,设置hadoop路径
2.打开 windowperspectiveopen perspectivemap/reduce
3.map/reduce locations,执行new hadoop location,编辑。
General
- map/reduce
12host:hadoop.dragon.org 自己绑定的域名port:9001- DFS master
12host:hadoop.dragon.org 位于同一台机器所以同map/reduceport:9000- location:hadoop 随便设
12username:hadoop 随便设SCKS proxy:保持默认Advanced parameters
修改hadoop.tmp.dir: /opt/data/tmp 与core-site.xml保持一值
修改dfs.permissions:false 连接上才能看到此参数
修改dfs.replication:1 伪分布设置副本数为1
4.运行还需添加如下jar包
commons-cli-1.2.jar、commons-logging-1.1.1.jar、 commons-configuration-1.6.jar、
commons-lang-2.4.jar、jackson-mapper-asl-1.8.8.jar、jackson-core-asl-1.8.8.jar
推测是配置的插件编译时没引入。
5.此时运行仍会遇到java.io.IOException: Failed to set permission
添加包org.apache.hadoop.fs,导入FileUtil.java文件。注释掉FileUtil.java中的checkReturnValue()方法。添加如下包commons-io-2.1.jar、commons-httpclient-3.0.1.jar
或者重新编译。
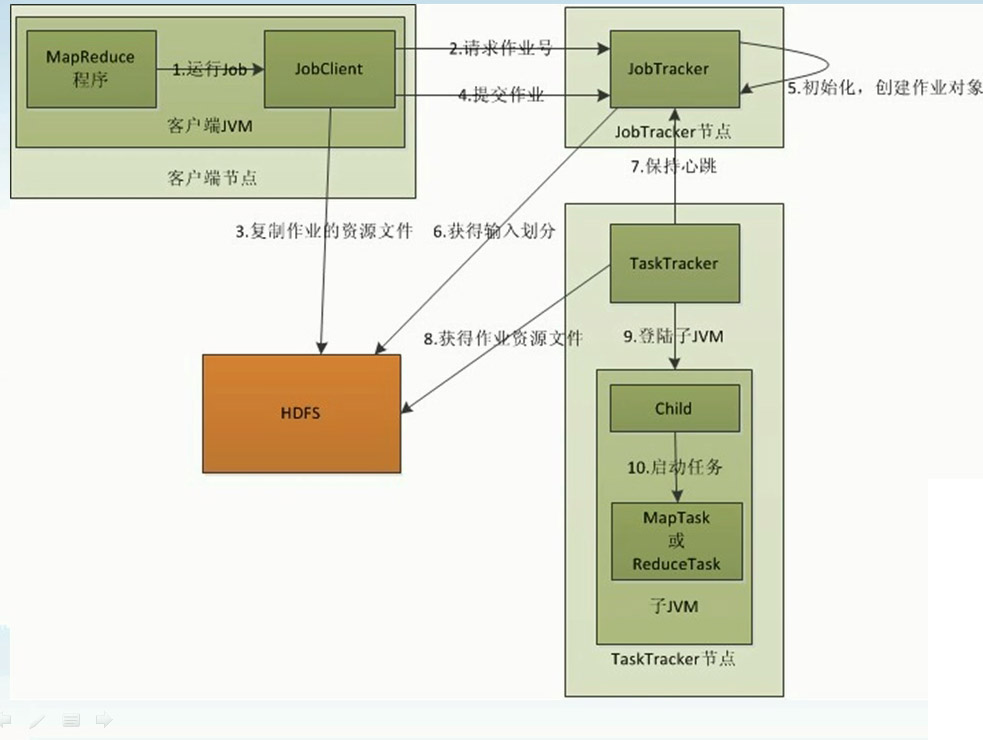
MapReduce作业运行分析
mapreduce作业运行整体分析
i.客户端启动一个作业
ii.向JobTracker请求一个JobID
iii.将运行作业所需的资源文件复制到HDFS上,包括MapReduce程序打包的Jar文件、配置文件和客户端所得的输入划分信息。这些文件都存放在JobTracker专门为该作业创建的文件夹JobID中。输入划分信息告诉了JobTracker应该为作业启动多少个Map任务信息。Jar文件默认有10个副本(由mapred.submit.replication属性控制)
iv.JobTracker接收作业后,将其放在一个作业队列里,等待作业调度器对其进行调度,当作业调度器根据自己的算法调度到该任务时,会根据输入划分信息为每个划分创建一个map任务,并将map任务分配给TaskTracker执行。对于map和reduce任务,TaskTracker根据主机数量和内存的大小有固定数量的map槽(即slot,hadoop2.x里为container)和reduce槽。map任务是不能随随便便分配给某个TaskTracker的,有个概念叫数据本地化(Data-Local)。即:将map任务分配给含有该map处理的数据块 TaskTracker上,同时将程序Jar包复制到该TaskTracker上来运行,这叫”运算移动,数据不移动”。而分配reduce任务时并不考虑数据本地化。
v.TaskTracker每隔一段时间会给JobTracker发送一个心跳,告诉JobTracker它依然在运行,同时心跳中还携带着很多的信息,比如当前map任务完成的进度等信息。当JobTracker收到作业的最后一个任务完成信息时,便把该作业设置成”成功”。当JobClient查询状态时,它将得知任务已完成,便显示一条信息给用户。
Map端流程分析
i.每个输入分片会让一个map任务来处理,默认情况下,以HDFS的一个块的大小(默认64M)为一个分片。map输出的结果会暂且放在一个环形内存缓冲区中(默认大小为100M,由io.sort.mb属性控制),当其溢出时(默认为缓冲区大小的80%,由io.sort.spill.percent属性控制),会在本地文件系统中创建一个溢出文件,将该缓冲区中的数据写入这个文件。
ii.写入磁盘之前,线程首先根据reduce任务的数目将数据划分为相同数目的分区,一个reduce任务对应一个分区的数据,避免了reduce任务数据分配不均。分区就是对数据进行hash的过程,再对每个分区中的数据进行排序,如果此时设置了Combiner,将会对排序后的结果进行Combine操作,目的是让尽可能少的数据写入到磁盘。
iii.当map任务输入到最后一个记录时,可能会有很多的溢出文件,这时需要将这些文件合并,合并的过程中会不断地进行排序和combine操作,这减少了每次写入磁盘的数据量,也减少了下一阶段网络传输的数据量,最后合并成一个已分区且已排序的文件。为了进一步减少网络传输的数据量,可以将数据进行压缩(mapred.compress.map.out设置为true)。
iv.JobTracker中保存了整个集群宏观的信息,只要reduce任务向JobTracker获取相对应的map输出位置,就可以将分区中的数据拷贝给相对应的reduce任务。
Reduce端流程分析
i.Reduce会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的。如果reduce端收受的数据量相当小,则直接存储在内存中(缓冲区大小由mapred.job.shuffle.input.buffer。percent属性控制,表示用作此用途的堆空间的百分比),如果数据量超过了该缓冲区大小的一定比例(由mapred.job.shuffle.merge.percent决定),则对数据合并后溢写到磁盘中。
ii.随着溢写文件的增多,后台线程会将它们合并成一个更大的有序的文件,这样做是为了给后面的合并节省时间。其实不管在map端还是在reduce端,MapReduce都是反复地执行排序,合并操作。
iii.合并的过程中会产生许多的中间文件(写入磁盘),但MapReduce会让写入磁盘的数据尽可能地少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到reduce函数。
Map shuffle phase
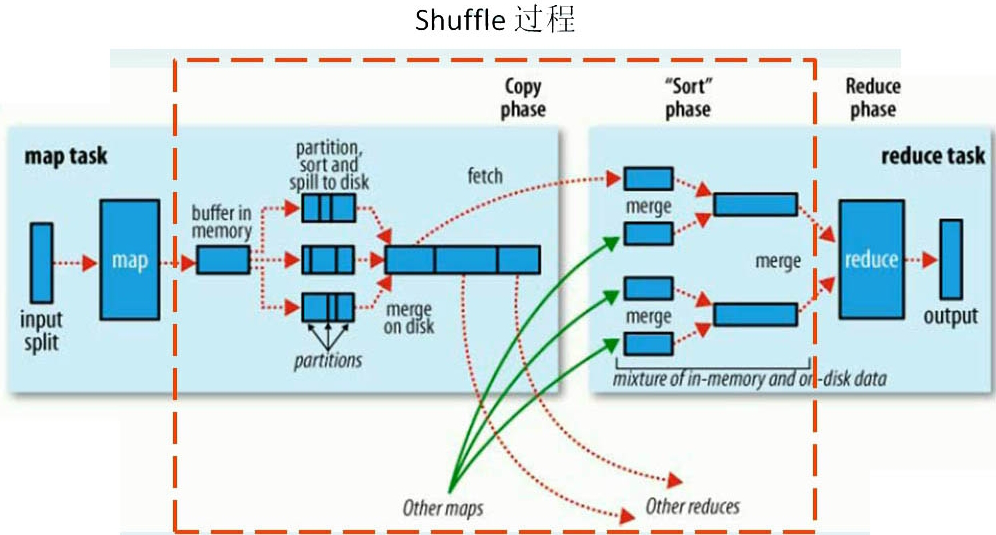
Shuffle 指从map task输出到reduce task 输入这段过程。
在map task执行时,它的输入数据来源于HDFS的block,map task只读取split。split与block的对应关系可能是多对一,默认是一对一。在WordCount里假设,输入数据是”aaa”这样的字符串。
mapper运行之后的输出是这样一个key/value对:key为”aaa”,value是1。map端只做加1的操作,在reduce task里才去合并结果集。例子中的job 有3个reduce task,当前的”aaa”将由哪个reduce去做,是需要现在决定的。
MapReduce提供Partitioner接口,作用就是根据key或value及reduce的数量来决定当前的输出数据最终应该将由哪个reduce task 处理。默认对key hash后再以 reduce task数量取模。默认方式只是为了平均reduce的处理能力,如果用户自己对Partitioner有需求,可以自定义并设置到job上。
在WordCount例子中,”aaa”经过Partitioner后返回0,也就是这对值应当将由第一个reducer来处理接下来,需要将数据写入内存缓冲区中,缓冲区的作用是批量收集map结果,减少磁盘IO的影响。key/value对以及Partition的结果都会被写入缓冲区。写入之前,key与value值都会被序列化成字节数组。
内存缓冲区有大小限制,默认是100MB。当map task的输出结果很多时,可能撑爆内存,所以需要在一定条件下将缓冲区的数据临时写入磁盘,然后重新利用这块缓冲区。这个从内存往磁盘写数据的过程被称为spill,即溢写。溢写是由单独线程来完成的,不影响入缓冲区写map结果的线程。溢写线程启动时不应该阻止map的结果输出所以整个缓冲区有个溢写的比例spill.percent。比例默认是0.8,即当缓冲区的数据已经达到阈值(buffer size spill percent = 100MB 0.8 = 80MB),溢写线程启动,锁定这80MB的内存,执行溢写过程。Map task的输出结果还可以往剩下的20MB内存中写,互不影响。
当溢写线程启动后,需要对这80MB空间内的key做排序(sort)。排序是MapReduce模型默认的行为,这里的排序也是对序列化的字节做的排序。
因为map task的输出是需要发送到不同的reduce端去,而内存缓冲区没有对将发送到相同reduce端的数据做合并,这种合并应该是体现在磁盘文件中的。如果有很多个key/value对需要发送到某个reduce端去,那么需要将这些key/value值拼接到一块,减少与partition相关的索引记录。
每次溢写会在磁盘上生成一个溢写文件,如果map的输出结果真的很大,有多次这样的溢写发生时,磁盘上相应的就会有多个溢写文件存在。当map task真正完成时,内存缓冲区中的数据也全部溢写到磁盘中形成一个溢写文件。最终磁盘中至少有一个这样的溢写文件存在(如果map的输出结果很少,当map执行完成后,只会生产一个溢写文件),因为最终的文件只有一个。所以要将这些文件归并到一起,即merge。有相同key的value merge成group。
group:对于”aaa”就是类似于:”{“aaa”, [5, 8, 2, … ] }“,数组中的值就是从不同溢写文件中读取出来的,然后把这些值加起来。由于merge是将多个溢写文件合并到一个文件,所以可能也有相同的key存在,在这个过程中如果client设置过Combiner也会使用Combiner来合并相同的key。
map端的工作结束后,最终生成的这个文件也存放在TaskTracker可以管理的某个本地目录内。每个reduce task不断地通过RPC从JobTracker那里获取map task是否完成的信息如果reduce task得到通知,获知某台TaskTracker上的map task执行完成,Shuffle的后半段开始启动。
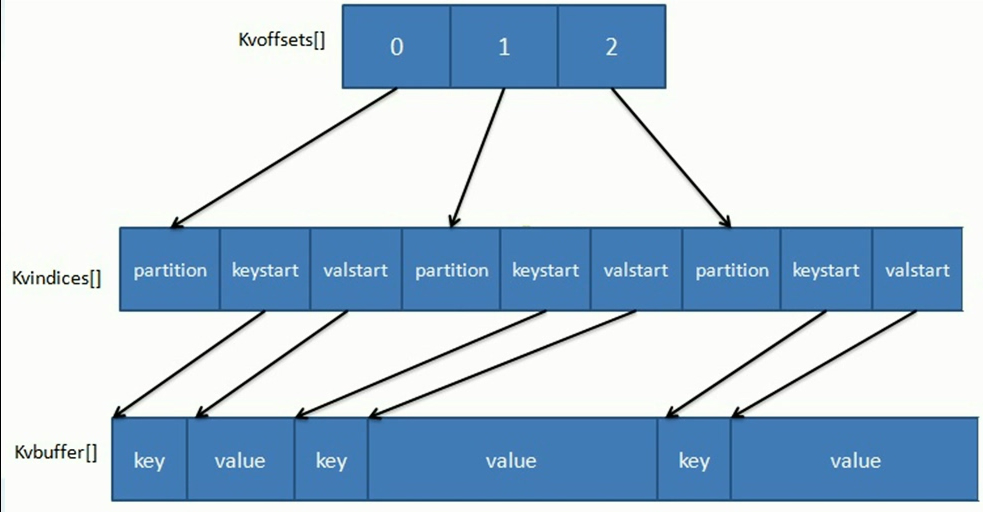
环形缓冲区
kvoffsets缓冲区,也叫偏移量索引数组,用于保存key/value信息在位置索引kvindices中的偏移量。当kvoffsets的使用率超过io.sort.spill.percent(默认80%)后,便会触发一次SpillThread线程的“溢写”操作,也就是开始一次Spill阶段的操作。
kvindices缓冲区,也叫位置索引数据,用于保存key/value在数据缓冲区kvbuffer中的起始位置。
kvbuffer即数据缓冲区,用于保存实际的key/value的值。默认情况下该缓冲区最多可以使用io.sort.mb的95%,当kvbuffer使用率超过io.sort.spill.percent(默认80%)后,便会发出一次SpillThread线程的“溢写”操作,也就是开始一次Spill阶段的操作。
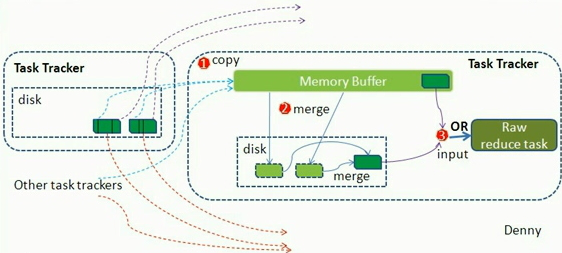
Reduce shuffle phase
reduce task 在执行之前的工作就是不断地取当前job里每个map task的最终结果,然后不断地进行merge操作,最终形成一个reduce task的输入文件。
copy过程,简单地取数据。Reduce 进程启动一些数据copy线程(Fethcer),通过HTTP方式请求map task所在的TaskTracker获map task的输出文件。由于map task已经结束,这些文件由TaskTracker管理在本地磁盘中。
merge阶段。这里的merge如map端的merge动作,只是数组中存放的是不同map端copy来的数值。copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置,因为shuffle阶段Reducer不运行,所以应该把大部分内存都给shuffle用。
merge有三种形式:内存到内存、内存到磁盘和磁盘到磁盘。默认第一种形式不启用,当内存中的数据量到达一定阈值,就启动内存到磁盘的merge。与map端类似,这也是溢写过程,如果设置了combiner,也是会启用的,然后在磁盘生成众多的溢写文件。第二种merge方式一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge方式生成最终的那个文件。
reducer输入文件。不断地merge后,最后会生成一个”最终文件”。这个文件存放于内存或磁盘中。对于我们来说,我们希望它存放于内存之中,直接作为reducer的输入,但默认情况下,这个文件是存放于磁盘中的。当reducer的输入文件已定,整个shuffle才最终结束。然后就是Reduce执行,把结果放到HDFS上。
对MapReduce的调优在很大程度上就是对MapReduce shuffle的性能的调优。
数据类型
1)在Hadoop中所有的Key/value类型必须实现Writable接口,有两个方法,分别用读(反序列化操作)和写(序列化操作)。
所有的Key,必须实现Comparable接口,在MapReduce过程中需要对Key/value对进行反复的排序,默认情况下依据Key排序的,要实现comparaTo()方法。
对此,Hadoop中有一个兼顾两者的接口WritableComprable。
2)由于key需要序列化、反序列化和比较,对Java对象需要重写以下几个方法。
equals()
hashCode()
toString()
3)数据类型,必须有一个默认的无参的构造方法,为了方便反射,进行创建对象。
4)在自定义数据类型中,建议使用Java原生数据类型,最好不要使用Hadoop对原生类型封装好的类型。
//后为封装的类型5)数据类型可实现RawComprarator接口,该接口允许直接比较数据流中的记录,
|
|
无须把数据反序列化为对象,这样便避免了新建对象的额外开销。
|
|
6)对于自定义Comparator类,需要以下几步:
推荐Comparator类定义在数据类型内部,静态内部类,实现WritableComparator类。
重写默认无参构造方法,方法内必须调用父类有参构造方法:
123public Comparator() {super.(MyWritable.class);}重载父类的compare()方法,依据具体功能进行覆写。
向WritableComparator类中注册自定义的Comparator类:
123static {WritableComparator.define(PairWritable.class, new Comparator() );}7)通常情况下,实现一个静态方法read(DataInput),用以构造数据类型的实例对象,方法内部调用readFileds(DataInput)方法。
Hadoop mapreduce data type 中所有的key,必须实现WritableComparator接口。
8)NullWritable和ObjectWritable
NullWritable是Writable的一个特殊类型,它的序列化长度为0。它并不从数据流中读取数据,也不写入数据。它充当占位符,如果希望存储一系列数值,与key/value相对,NullWritable也可以用作在SequenceFile中的键。它是一个不可变的单实例类型:通过调用NullWritable.get()方法可以获取这个实例。
ObjectWritable是对Java基本类型(String, Enum, Writable,null或这些类型组成的数组)的一个通用封装,它在Hadoop RPC中用于对方法的参数和返回类型进行封装和解封装。当一个字段包含多个类型时,ObjectWritable是非常有用的。
Mapper类和Reducer类
Mapper类
API文档
1)InputSplit 输入分片,InputFormat输入格式化
2)对Mapper 输出数据进行 Sorted排序和Group分组
3)对Mapper输出数据依据Reducer个数进行分区Partition
4)对Mapper输出数据进行Combiner
方法:
第一类,protected类型,用户根据实际需要进行重写
1)setup:每个任务执行前执行一次,对Map Tast进行一些预处理
2)map:每次接受一个key/value对并对其进行处理,再分发处理
3)cleanup:每个任务执行结束调用一次,对Map Task进行一些处理后的工作
第二类,运行的方法
run()方法,是Mapper类的入口,相当于Map Task的驱动,方法内部调用了setup()、map()、cleanup()。
Reducer类
功能说明
获取map()方法输出的中间结果
将中间结果中的value按照Key划分组(group),而group按照key排序,形成了
处理group中的所有value,相同key的value组合。最终key对应的value唯一,
案例
案例1:TopKey
算法实现
某个文件中革某列数据的最值(最大或最小)
某个文件中某列数据的Top Key值(最大或最小)
文件中某列数据的Top Key值(最大或最小)
统计和TopKey
数据格式:
语言类别 歌曲名称 收藏次数 播放次数 歌手名称
需求:
统计前十首播放次数最多的歌曲名称和次数
案例2:手机上网流量统计
1)分析业务需求:用户使用手机上网,存在流量的消耗。流量包括两个部分: 上行流量(发送信息流量);下行流量(接收信息流量)。每种流量在网络传输过程中,有两种形式的说明:包的大小,流量的大小。使用手机上网,以手机号为唯一标识符进行记录。
需要的字段:手机号码、上行数据包数、下行数据包数、上行总流量和下行总流量2)自定义数据类型:
DataWritable 实现WritableComparable接口。3)分析MapReduce写法,哪些业务逻辑在Map阶段执行,哪些业务逻辑在Reduce阶段执行。
4)Map阶段:从文件中获取数据,抽取需要的五个字段,输出的Key为手机号码,输出的value为数据流量的类型DataWritable对象。
Reduce:阶段将相同手机号码的value中的数据流量进行相加,得出手机流量的总数(数据包和数据流量)。输出到文件,以制表符分开。5)测试。
MapReduce配置和其它
MapReduce配置
最小配置的MapReduce,读取输入文件中的内容,输出到定制目录的输出文件夹中,此时文件中的内容为
Key: 输入文件每行内容的起始位置
Value: 输入文件每行的原内容
输同文件的内容就是:Key + \t + value
依据模板类编写WordCount
1)修改名称(MapReduce类的名称,Mapper类的名称和Reducer类的名称)
2)依据实际业务逻辑,修改Mapper类和Reducer类的Key/Value输入参数的类型
3)修改驱动Driver部分Job的参数设置(Mapper类和Reducer类的输出)
4)在Mapper类中编写实际的业务逻辑(setup()、map()、cleanup())
5)在Reducer类中编写实际的业务逻辑(setup()、map()、cleanup())
6)检查并修改驱动Driver代码(模板类的run()方法)
7)设置输入输出路径,进行MR测试。
打印信息
告知输入路径下有几个文件需要进行处理
1INFO input.FileInputFormat: Total input paths to process : 1加载本地的Hadoop文件,默认的情况下,在Hadoop 1.x中存放于$HADOOP_HOME/c++/Linux-amd64-64/lib/
1INFO util.NativeCodeLoader: Loaded the native-hadoop library加载本地的Snappy压缩算法的库存,默认情况下,Linux是没有相应的库存,需要用户进行配置
INFO util.NativeCodeLoader: Loaded the native-hadoop library
运行JOB的相关进度信息
运行JOB的ID
1INFO mapred.JobClient: Running job: job_201509071500_0001JOB运行时的Map Task和Reduce Task的运行进度
123INFO mapred.JobClient: map 0% reduce 0%INFO mapred.JobClient: map 100% reduce 0%INFO mapred.JobClient: map 100% reduce 100JOB运行完成
1INFO mapred.JobClient: Job complete: job_201509071500_0001显示整个JOB运行过程,各类计数器Counter 的值,一共有29种五大类
|
|
计数器
MapReduce计数器为我们提供一个窗口,用于观察MapReduce Job运行期的各种细节
Map-Reduce Framework包含了相当多的Job执行细节数据,一般情况下record表示行数据,byte表示行数据所占字节
File Input Format Counters 和File Output Format Counters对应,包含输入输出文件大小的信息。
FileSystemCounters

- Job Counters,描述与job调度相关的统计
| Counter | Map | Reduce | Total |
|---|---|---|---|
| Data-local map tasks | 0 | 0 | 67 |
| FALLOW_SLOTS_MILLIS_MAPS | 0 | 0 | 0 |
| FALLOW_SLOTS_MILLIS_REDUCES | 0 | 0 | 0 |
| SLOTS_MILLIS_MAPS | 0 | 0 | 1,210,936 |
| SLOTS_MILLIS_REDUCES | 0 | 0 | 1,628,224 |
| Launched map tasks | 0 | 0 | 67 |
| Launched reduce tasks | 0 | 0 | 8 |
Data-local map tasks
Job在被调度时,如果启动了一个data-local(源文件的幅本在执行map task的taskTracker本地)
FALLOW_SLOTS_MILLIS_MAPS
当前job为某些map task的执行保留了slot,总共保留的时间是多少
FALLOW_SLOTS_MILLIS_REDUCES
当前job为某些reduce task的执行保留了slot,总共保留的时间是多少
SLOTS_MILLIS_MAPS
所有map task占用slot的总时间,包含执行时间和创建/销毁JVM的时间
SLOTS_MILLIS_REDUCES
所有reduce task占用slot的总时间,包含执行时间和创建/销毁JVM的时间
Launched map tasks
此job启动了多少个map task
Launched reduce tasks
此job启动了多少个reduce task